Sorry, I find this hard to believe. Weren’t there other papers that have data problems that are associated with this professor? Was the same RA involved in all of them too?
Okay, I’m going to give a preview of a podcast I’m planning on doing later in the week.
I was an RA for some physics profs, where I ran/adjusted the code (I think it was in C… but it could’ve been FORTRAN… I know lots of languages). As a result, I have official, peer-reviewed papers to my name. I did some adjustments to the code, made runs, and I made the one graph that appeared in the papers. And I got attribution. Those papers had 4 authors (including me).
Similarly, in math, if an RA contributed to a paper, they got attribution.
But I know that’s not the case in many fields. Especially social sciences.
Frankly, I could totally believe both Ariely and Gino don’t have enough technical know-how to tamper with the data well enough to get the results they needed. Hell, I wouldn’t be surprised that neither of them did any statistical analysis at all – that was the RA’s purview, after all. They do the number-crunching, give you the p-hacking results, and then the profs do the the paper write-ups.
They may have directed an RA to make changes to get the results they wanted. I highly doubt they said anything that crass. They could have “encouraged” [wink wink] to improve the results.
Or they could have rewarded the magical RA who got them the awesome results/analysis they had been looking for.
And for all I know there was more than one, but the magical RA may not have been feeling too generous in explaining how they got their magical results, because this is a “tournament” career, where there are few slots for people to take. They would not get rewarded for helping fellow RAs.
1 Like
I suppose I am just a sweet summer child. I can barely wrap my head around that possibility.
https://twitter.com/owenboswarva/status/1688975359604101129
Catastrophic PSNI blunder identifies every serving police officer and civilian staff, prompting security nightmare https://belfasttelegraph.co.uk/news/northern-ireland/catastrophic-psni-blunder-identifies-every-serving-police-officer-and-civilian-staff-prompting-security-nightmare/a1823676448.html?=123… #FOI #dataprotection Spreadsheet disclosed via
earlier today (now removed) https://whatdotheyknow.com/request/numbers_of_officers_and_staff_at

There are a tiny number of individuals whose unit is given as “secret”. But although that does not disclose precisely what they do, it marks them out as operating in an acutely sensitive area – and then gives their name.
There are details of the specialist firearms team, of riot police – the TSG unit – and the close protection unit which guards senior politicians and judges.
There is even a list of people responsible for “information security”.
It is a breathtaking exposure of PSNI secrets.
One former senior PSNI officer told the Belfast Telegraph that it was “astonishing” and a “huge operational security breach”.
“This is the biggest data breach I can recall in the PSNI,” he said.
This is not a new issue – I’ve used this example of gene names getting converted to dates in Excel in SOA presentations and articles going back to 2016, iirc.
Guest post: Genomics has a spreadsheet problem – Retraction Watch>
Gene-name errors were discovered by Barry R. Zeeberg and his team at the National Institutes of Health in 2004. Their study first showed that when genomic data is handled in Excel, the program automatically corrects gene names to dates. What’s more, Riken clone identifiers – unique name tags given to pieces of DNA – can be misinterpreted as numbers with decimal points.
In 2016, we conducted a more extensive search, showing that in more than 3,500 articles published between 2005 and 2015, 20% of Excel gene lists contained errors in their supplementary files.
…
In response to these issues, the HUGO Gene Nomenclature Committee (HGNC) has made changes to some gene names prone to errors. This includes converting the SEPT-1 gene to SEPTIN1 and the MARCH1 gene to MARCHF1.The widespread adoption of these new names is a lengthy process: Our latest study, of more than 11,000 articles published between 2014 and 2020, found that 31% of supplementary files that included gene lists in Excel contained errors. This percentage is higher than in our previous 2016 study.
So, they did a study, and found about 20% had the problem.
They tried to fix the problem - publicize it, fix the names of some of the genes, etc.
Redid the study… 31% had the problem.
Yay.
2 Likes
Continuing the Data Colada saga (now with lawsuit!)
Because of the lawsuit, the DC guys have gotten the Harvard investigation result and have gotten to see just how correct they were in their data fraud detection:
Gino’s lawsuit (.htm), like many lawsuits, contains a number of Exhibits that present information relevant to the case. For example, the lawsuit contains some Exhibits that present the original four posts that we wrote earlier this summer. The current post concerns three other Exhibits from her lawsuit (Exhibits 3, 4, and 5), which are the retraction requests that Harvard sent to the journals. Those requests were extremely detailed, and report specifics of what Harvard’s investigators found.
Specifically, those Exhibits contain excerpts of a report by an “independent forensic firm” hired by Harvard. The firm compared data used to produce the results in the published papers to earlier versions of data files for the same studies. According to the Exhibits, those earlier data files were either (1) “original Qualtrics datasets”, (2) “earlier versions of the data”, or (3) “provided by [a] research assistant (RA) aiding with the study”. We have never had access to those earlier files, nor have we ever had access to the report that Harvard wrote summarizing the results of their investigation.
For all four studies, the forensic firm found consequential differences between the earlier and final versions of the data files, such that the final versions exhibited stronger effects in the hypothesized direction than did the earlier versions. The Exhibits contain some of the firm’s detailed evidence of the specific discrepancies between earlier and published versions of the datasets.
Example:
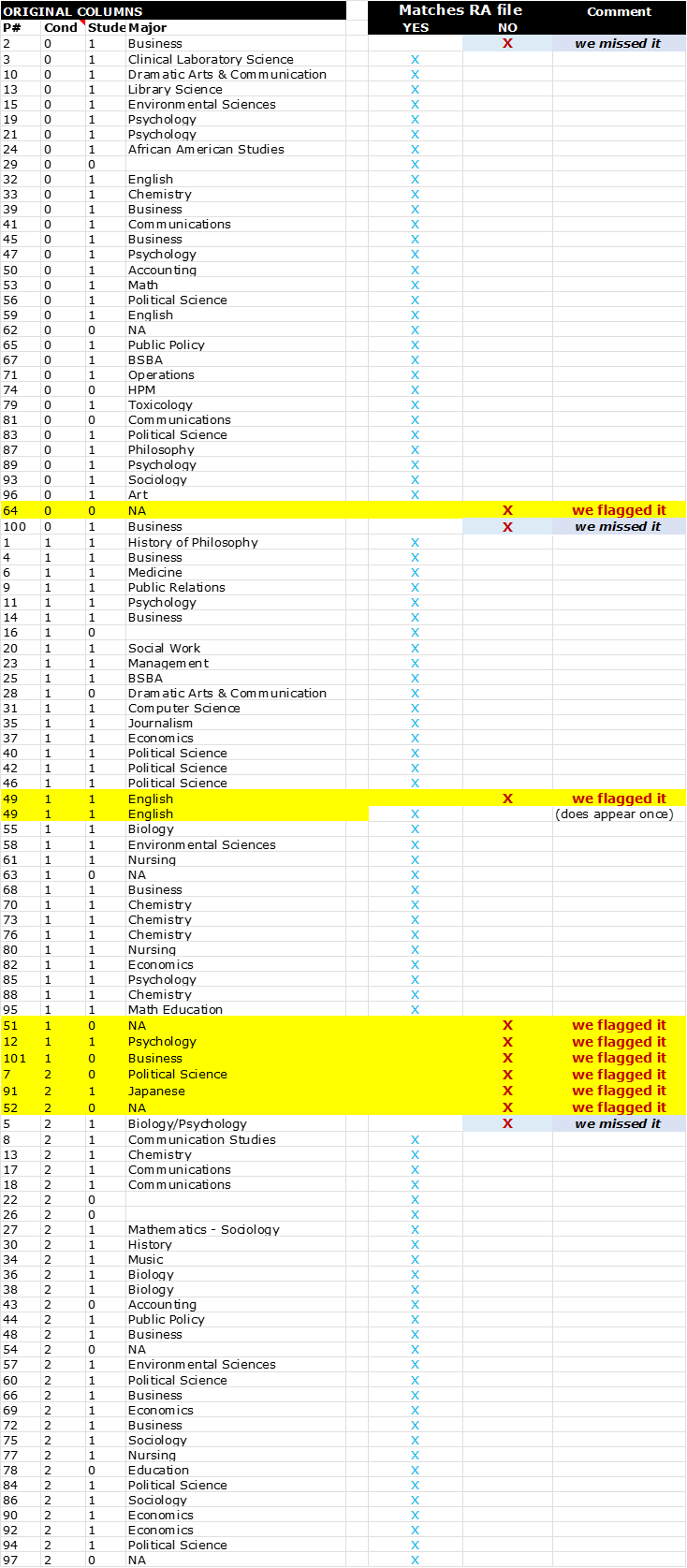
If you can’t see, they show which ones they flagged – and every single one of those had been tampered with.
There were 3 additional records that were tampered with that they had missed.
2 Likes
Gino and Wiltermuth (2014) reported that people who cheated on one task were more creative on subsequent unrelated tasks… It also shows evidence that the independent variable – whether or not a participant cheated – was tampered with.
They cheated on a study about cheating.
Yes, that’s what I said:
And:
That’s right:
Two different people independently faked data for two different studies in a paper about dishonesty.
Oh, I missed that, sorry.
A bit like method acting - they were trying to put themselves in the cheaters shoes.
1 Like
The thing is, who did the peer review at the journals before the results were published?
Got through the checks there as well.
That’s what I said in many of these cases, too.
Hey, maybe you can mark down professionalism credits by listening to my podcast (it’s free!)
I discuss ASOP 23, spreadsheets & data distortion from Excel, and it runs about 50 minutes (at 1x speed), so that should count for 1 credit, professionalism. At least in the U.S.
![]()
5 Likes
via EuSprIG mailing list:
An myriad of poor practice and error in a spreadsheet created by the Anaesthetic National Recruitment Office (ANRO) for calculating and aggregating interview scores for trainee anaesthesiologists made all of the candidates “unapointable” in Wales. A review that followed found that the spreadsheet lacked a template, a standard naming convention, labels and structure. There were also issues with manual transfer of data between regional spreadsheets and a master spreadsheet, issues with copy and paste and VLOOKUP.
Sounds to me like an unmitigated mess, a “frankensheet” that no one is really sure about. I would think that a lot of middle management, regardless of the domain, use Excel in this hacky way. It really underlines why basic checking should be applied before decisions are made and that having some predefined standards can cut out a lot of variation which causes great problems when consolidating disparate sources.
Excel bungling makes top trainee doctors ‘unappointable’ • The Register
This is why large corporations are so obsessive about EUCs now.
Far too many processes were basically dumpster fires due to poor spreadsheet design and controls.
As usual, the public sector is very far behind the curve.
This is true about many standards (I need not build a litany) about governmental agencies, mainly due to no consequences.
Here is another piece on the screw-up (also with a weird typo for referring to VLOOKUP)
So here’s the deal: there were only 24 people interviewed. One would imagine that it’s relatively simple to at least spot-check that the ranking was correct when it’s only 24 people. They switched the highest- and lowest-ranked. Among other issues. It’s ridiculous.
It sounds to me like the people operating these excel processes have really poor IT and quantitative skills in general.
These are basic things they screwed up. There is no excuse for that at that level.
And here’s part 2, which is really about modeling standards (ASOP 56)
This has been a big topic of discussion in EuSprIG the last few days…
A Cambridge NHS trust has admitted two historic data breaches, stemming from the accidental disclosure of patient data in Excel spreadsheets in response to Freedom of Information (FOI) requests.
Cambridge University Hospitals NHS Foundation Trust CEO, Roland Sinker, revealed the news yesterday, explaining that the first incident occurred in 2021 but had only “recently” come to light.
“The first case related to data provided in a FOI request via the What Do They Know website. In responding to the request, we mistakenly shared some personal data which was not immediately visible in the spreadsheet we provided but which could be accessed via a ‘pivot table’,” he explained.
The issue was that they shared it with a pivot table… and, as you know, double click and -boom- you can see the underlying data.
The way this data was leaked is almost identical to the far graver breach at the Police Service of Northern Ireland (PSNI) earlier this year. The police service also accidentally shared sensitive information with What Do They Know in response to an FOI request, with the data hidden by a pivot table.
So maybe some of us can see the very annoying practice of data being shared via PDF in response to FOIA requests - they may have been burned in the past from this kind of crap. Rather than risk having too much embedded in whatever database extract by accident, (and not having to explain that what-you-see-is-the-minimum-of-what-you-get-you-might-be-getting-more), PDF (currently) guarantees there aren’t extra data coming along for the ride.
1 Like
Another reason why I don’t use Pivot tables when there are perfectly cromulent and documentable methods instead.
Also, why didn’t they simply Paste-Special Values the Pivot Table result to a new spreadsheet? Do they know that even exists??
3 Likes