Yes, and same solution. Don’t teach how to add numbers, teach how addition works. Same thing, but probably going forward to an even greater extent than in the past.
There is another part to it. We have to learn to decide which calculation to do, the inputs, and how to use the results.
In other words, we give context to the calculation based on environment, action, values, and often community (who will be using it.)
I think the same will be true of these LLM model results.
I also think it’s important when understanding these models not to put too much emphasis on a particular conception of ideal reason as a series of mechanical symbol manipulations devoid of context and values.
Instead we have to see rationality as also depending also on a set of relationships and values. LLMs have neither of these.
I feel bad for teachers right now. They can’t stop their students from cheating on everything. The best solution is probably to force them to take tests on paper or locked-down devices. Which is a pretty lame way to approach learning. (Although very actuarial)
Aside from that, I think schools should be waiting for the dust to settle.
Managers, of course, need to figure things out right now. And it’s not easy for them.
There is a lot of gossip about what happens when like Senior Software engineers retire, but nobody hires Junior Software engineers. I feel like that is both eons away, and also a good problem for the free-market to address.
We see this now, a bit, with dead programming languages like COBOL, and we handle it okay I think?
If nothing else, I think we can devise professional training that doesn’t rely on decades of work experience. Especially if we are assuming that the employment in these fields is actually decimated, and the remaining few are ultra-productive.
Some notes:
-
this study was done by law professors, not ai bros, adding legitimacy.
-
I’m a little surprised they chose to fund this study, because I assume most fields don’t want to undermine their own professionals.
-
contract law doesn’t always have a “right” or “wrong” answer. This is the first? professional study I’ve seen where we look at subjective answers. I’m wondering if more will follow.
-
the AIs didn’t just tie the law professors, they crushed them. It makes you feel like there’s no reason you’d ever contact your prof during office hours when the bot has a better answer. (Better defined here as both “preferred” and less likely to be “harmful”/misleading)
-
it also makes me wonder how long it will take for normal people to realize that AI has great short-answers about contract law disputes, apparently.
-
the AI that did best (they all did great) was Gemini 2.5. Not NotebookLM with RAG and the casebook, nor the actual “Legal AI” product that is especially trained. Just boring stupid Gemini. In other words, not a special “legal” or “research” AI.
-
finally. A common problem with studying LLMs is that better ones come out before the study is published. To address this they trained an AI to replicate the human judgments and found (tentative) evidence that Claude is now even more absurdly ahead. This is an interesting approach imo. Obviously people who are skeptical of all things AI will balk at using AI to judge AI, but presumably those looking for a “best in class” will want it.
In my experience, “professional training”–no matter how good or extensive it might be–isn’t the same thing as actual experience.
In fact, the better professional training that I’ve been a part of (on both sides of that equation) are derived from decades of work experience.
And professional training isn’t nearly as good at getting you prepped for “the unexpected” nearly as well as “decades of experience”. I think it’s valuable, but I’ve seen that the latter are often looked to for guidance and how to use the former when that “unexpected” happens.
1 Like
I think it’s appropriate that this study was aimed at “law school tutoring.” It doesn’t surprise me if a law professor isn’t the best at answering common law students questions particularly about areas not concerning their particular taught class. Even in research areas, they might do worse; sometimes knowing more hurts more than it helps when answering questions for a class.
One interesting comparison: how well would law students have done themselves given access to google (before LLM augmentation let’s say)? Another: how well would they do with an internet search allowed to use “dense embedding” to augment the search?
1 Like
These are all contract law professors all teaching from the same casebook, answering questions relevant to their class.
Or do you mean “professors are terrible at teaching 1st year students, because it’s a side-gig?” I guess could be true, though also pretty damning.
Sounds interesting.
The question that would have been interesting to ask, but doesn’t seem to have been asked is: What was it about the AI answers that left them more satisfied?
I’m wondering if the writing is better. When I’m peer reviewing science manuscriptor reading other people’s writing, I find a lot of people aren’t very good writers. I’ll note that I’m reading manuscripts that have probably been reviewed and revised at least 4 or 5 times, quite possibly more, prior to submission by authors and co-authors. Also, people are lousy with punctuation, including myself.
I also wonder if the AI is possibly better at summarising and avoiding distractions. I could see a lot of profs going on tangents about their favourite cases that are relevant to a situation. Is AI more on point about the general scenario, but weaker on the exceptions.
2 Likes
They do try to pick at this a bit…
from the paper–
chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://law.stanford.edu/wp-content/uploads/2026/06/salinas_et_al.pdf
(page 9 and the graph on page 10)
Textual features only partially account for the LLM advantage. Is the LLM advantage plausibly driven by how the answer is written or by what the content of the answer is? To investigate this question, we generate several textual features of answer quality informed by best practices in the AI tutor and AI education literature (20; 27; 29; 37). In particular, we measure an answer’s structural organization, reasoning nuance, legal anchors, confidence tone, clarity, pedagogical support, and length. All of these features are based on lexical/syntactic information and do not take into consideration semantic content. Figure I.1 in Supplementary Information I shows that only answer length is significantly positively correlated with a higher win rate, whereas clarity (Flesch reading-ease score (38)) and pedagogical support (the sum of the rate of question marks and the scaffolding rate per answer (39; 40)) are negatively correlated with answer win rate. We note, however, that none of these estimates can be understood causally absent strong assumptions.
More importantly, Figure 3 compares observed LLM win rates against predicted win rates estimated purely from these textual features and shows that LLMs consistently perform better than expected, based on their lexical/syntactic features only. The difference is particularly pronounced for the decile with the lowest predicted win rate. These results suggest that the LLM advantage cannot be fully explained by common textual features, lending support to the hypothesis that the answer quality is at least partly driven by the content of the answer.
I didn’t realize it was from classes they were all teaching. Your quote above may be true; for many professors, it really is a side gig, or at least certainly doesn’t have much bearing on whether they keep a job.
I’d also be curious if the LLM’s tendency to return an “average” answer isn’t what makes it more acceptable to the majority of professors.
1 Like
Sure, maybe the LLM is a sort of “median” professor, winning by being minimally offensive. I’m not sure if they tested that hypothesis anywhere, maybe.
1 Like
I saw a quote in a NYT article: The Oxford economist Carl Benedikt Frey puts it plainly: “Most economists will acknowledge that technological progress can cause some adjustment problems in the short run. What is rarely noted is that the short run can be a lifetime.”
I did the logical thing and copied/pasted that quote into Google’s AI. It said “True. Do you want me to give you some historic examples?”
I said “sure”, so it gave me four. The first was the the original Luddite issue, the hand weavers replacement. Google found a Wikipedia article saying that this coincided with a 50-year stretch where British GDP per capita soared, but real wages completely stagnated. Thousands of individual weavers never recovered.
Then the second industrial revolution, the rust belt manufacturing collapse, and the white collar losses in the 2007-2009 recession. Time frames were shorter than 50 years, but in all cases older workers suffered permanent wage losses.
3 Likes
I don’t dispute that there can be a rough adjustment period. But every other time we’ve thought, welp, no more need for human labour, we’ve found something.
Tax capital adequately and it’s still fine, we can share the gains. I don’t see that happening for a while though.
I agree with both sentences. We should have been taxing capital more even before AI, now it’s even more important.
And, I don’t see the political will to do it, or the super knowledge to spend the taxes effciently. (but, less than efficient would still be better than nothing)
I wonder a bit about how much impact AI is going to have. If you’re mostly programming a computer I can see where you’re potentially in trouble. If you’re a nurse, plumber or carpenter not so much. Probably also pretty safe if you’re a doctor. The value of AI starts to plummet pretty quickly once you do stuff that doesnt involve a computer.
In Canada, we’re begging for more doctors, nurses, and many types of trades people. We probably also need farmers and fish harvesters. I wonder if AI leads to a realignment of where people look for jobs that perhaps better aligns with our needs.
2 Likes
Agree with this:
The challenge for proponents of AI is that the economic pain will be more frontloaded and visceral than any gains in productivity and jobs. It takes time for industries to optimise their use of technology to create new value and openings. Automation also threatens elites in influential white-collar sectors, amplifying potential resistance.
AI resistance is very much concentrated in developed economies that are services driven.
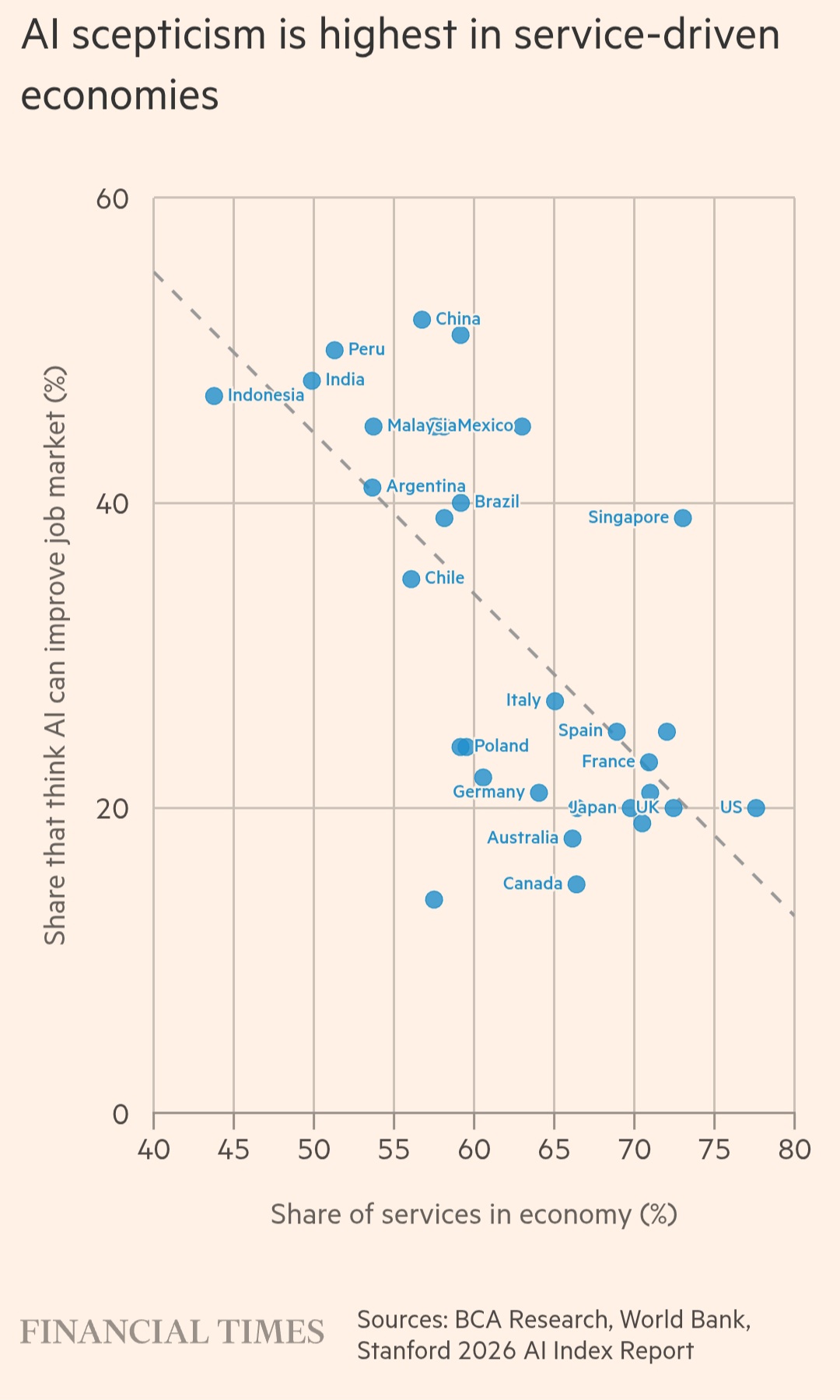
There’s an implicit bias not disclosed here . . .
I would posit a plausible answer might very well be that the AI just gives them the answer rather than a “Socratic” learning experience. (Note that I’m not looking to address the “side-gig” situation in this post.)
FWIW, I think there is a place for both types of “tutoring” . . . but the AI “just give them the answer” has the drawback of not encouraging critical thinking skills. The Socratic method has the drawback of delayed learning due to frustration in the professor not really understanding where the student’s thought-model is currently set.
Ai doesn’t have to replace, it can extremely augment.
I think im about a month away from having a variety of custom enterprise level systems in place. Lil ole me, with analytics and software processes only previously available to larger companies.mmim going to be optimizing everything. My whole business is going to be impacted, even if my base job function is the same.
My son in law is a carpenter with one employee. hes not getting replaced, but he can have his own 3d modelling software, something individuals like him generally don’t have. and likely more tools as he figures out that he can have whatever he wants.
There’s a farmer here locally who’s pretty high tech. Once he figures out he can have whatever optimization software he wants, it’ll be on like donkey kong.i dunno, maybe he starts running analytics on yields against weather and local inputs. I dunno, but he’s already doing some crazy stuff that he paid big dollars for. Once he can have what he wants without the price tag, gonna be interesting. The barrier to software is gone.
It’s the professors who were surveyed, not the students. Presumably, if the professors preferred Socratic responses, they would rank themselves above the AI.